首先什么是小领域知识库
在知识领域研究的人群应该对知识图谱有了一个大概的了解,此处不再对知识图谱再次科普,我将直接介绍知识库。知识库是存储类似于(主-谓-宾)的三元组,三元组的表述方式一般为(头实体-关系-尾实体)。往往现存的知识库是从一些百科上爬虫下来的全领域知识。往往我们在做数据分析时这样90%的数据就是领域之外的数据,将所有数据放入模型将会造成大量的冗余计算。
因此,引出了小领域知识库,将所需的领域知识库从全知识库中剥离出来,将会大大降低后续研究工作的复杂度。
如何构建小领域知识库
介绍完了小领域知识库的概念和构建动机。了解到小领域知识库的实体搭建。
命名实体识别(实体构建:
使用thulac工具进行分词,词性标注,命名实体识别(仅人名,地名,机构名) 为了识别农业领域特定实体,我们需要:
1.分词,词性标注,命名实体识别
2.以识别为命名实体(person,location,organzation)的,若实体库没有,可以标注出来
3.对于非命名实体部分,采用一定的词组合和词性规则,在O(n)时间扫描所有分词,过滤不可能为农业实体的部分(例如动词肯定不是农业实体)
4.对于剩余词及词组合,匹配知识库中以分好类的实体。如果没有匹配到实体,或者匹配到的实体属于0类(即非实体),则将其过滤掉。
5.实体的分类算法见下文。
实体分类:
特征提取:
分类器:KNN算法
无需表示成向量,比较相似度即可
K值通过网格搜索得到
定义两个页面的相似度sim(p1,p2):
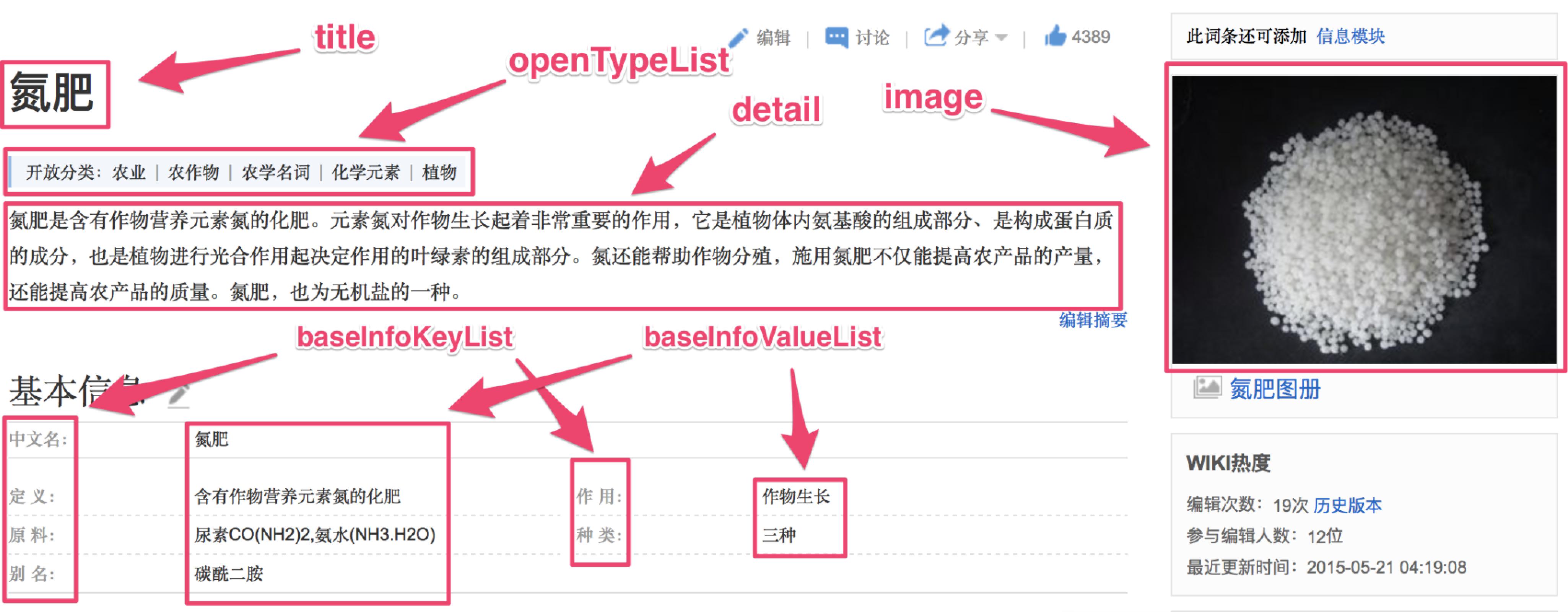
1.title之间的词向量的余弦相似度(利用fasttext计算的词向量能够避免out of vocabulary)
2.2组openType之间的词向量的余弦相似度的平均值
3.相同的baseInfoKey的IDF值之和(因为‘中文名’这种属性贡献应该比较小)
4.相同baseInfoKey下baseInfoValue相同的个数
5.预测一个页面时,由于KNN要将该页面和训练集中所有页面进行比较,因此每次预测的复杂度是O(n),n为训练集规模。在这个过程中,我们可以统计各个分相似度的IDF值,均值,方差,标准差,然后对4个相似度进行标准化:(x-均值)/方差.
6.上面四个部分的相似度的加权和为最终的两个页面的相似度,权值由向量weight控制,通过10折叠交叉验证+网格搜索得到。
Labels:(命名实体的分类)
